고정 헤더 영역
상세 컨텐츠
본문
- 본 글에서는 CV 분야에서 사용되는 Generative Adversarial Network 대해 간단히 소개합니다.
1. Concept
큰 틀에서 신경망을 구성할 때 볼 때 숫자를 줄이는 과정이 인코딩, 늘리는 과정이 디코딩이라고 피상적으로 이야기 할 수 있습니다. 조금 더 구체적으로 이야기하자면, 어떤 데이터(이미지나 텍스트)에서 의미있는 정보를 뽑아내는 과정을 인코딩, 이 반대로 생성하는 과정을 디코딩이라고 생각할 수 있습니다. GAN은 인코딩과 디코딩을 활용하여 적절한 Image를 생성해내는 모델입니다.

확률 분포는 GAN와 밀접한 연관이 있습니다. GAN는 데이터를 통해 내부적으로 데이터에 대한 확률 분포를 만들고, 이에 따라 데이터를 생성합니다.

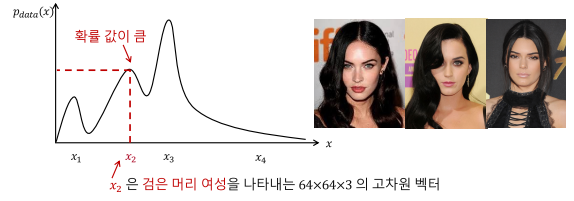

예를 들어, 이미지 데이터를 통해 확률 분포를 만들었다면 입력 데이터에 따라 위와 같은 확률분포가 생성될 수 있습니다. Dencity Model은 Implicit한 모델과 Explicit한 경우가 있습니다. Explicit한 경우 Dencity를 추정할 때 수식으로 명확하게 표현할 수 있습니다. 반대로 Implicit한 경우 추정할 때 사용한 수식을 깔끔하게 표현하지 못합니다. GAN에 사용되는 Dencity Model은 Implicit한 형태로 명확한 표현은 불가능하지만, 내부적으로는 존재하여 작동합니다.
2. Algorithm

이제 GAN에 대해 직관적인 이해를 위해 한가지 예시를 보겠습니다. 먼저 어떤 특정 실제 이미지 x에 대해 Discriminator 신경망은 D(x)가 최대한 1에 가깝게 파라미터를 조정합니다.

또한 동일한 Discriminator 신경망은 D(G(z))가 최대한 0에 가깝게 파라미터를 조정합니다. 이 때 G(z)는 Generator가 만든 가짜 이미지입니다.

D의 입장에서 D(G(z))가 0에 최대한 가깝게 파라미터를 조정하는 동안, Generator신경망 역시 D(G(z))가 최대한 1에 가깝게 파라미터를 조정해나갑니다. 이는 Generator가 실제와 가짜를 구분하기 어려운 이미지를 생성하기 위함입니다.
직관적으로 보자면, D는 최대한 가짜 이미지를 구별하기 위해 학습하며, G는 최대한 가짜 이미지를 진짜처럼 보이게 하기 위해 학습하는 것입니다.

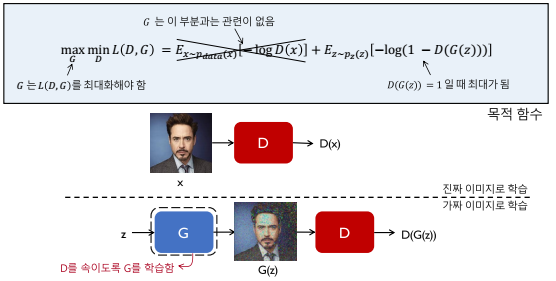
이제 수학적으로 D와 G가 어떻게 학습하는가에 대해 살펴보겠습니다. 먼저 D는 실제 이미지는 실제 이미지라고 판단해야하고, 가짜 이미지는 가짜 이미지로 판단해야합니다. 이에 따라 D는 목적함수L(D,G)를 최소화 하는 방향으로 학습합니다.
D의 목적함수는 두 부분으로 나누어 볼 수 있습니다. 목적함수의 앞 부분은 실제 데이터가 입력되었을 때 실제 데이터라고 인식하도록 학습하도록하고, 뒷 부분은 가짜 데이터가 입력되었을 때 가짜 데이터로 인식하도록 학습하는 부분입니다.
반면, G는 목적함수L(D,G)를 최대화하여 D를 속일 수 있는 G(z)를 만들 수 있도록 학습합니다.
'ML' 카테고리의 다른 글
| Attention Usage (0) | 2022.12.19 |
|---|---|
| Recurrent Neural Networks (0) | 2022.12.16 |
| Convolution Neural Network (0) | 2022.12.14 |
| Hyper Parameter (0) | 2022.12.12 |
| 신경망(Neural Network) (1) | 2022.12.08 |





댓글 영역