고정 헤더 영역
상세 컨텐츠
본문
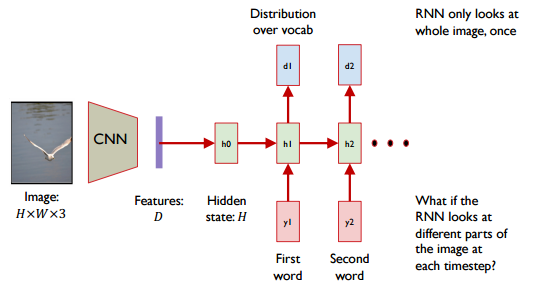
하나의 이미지를 글로 표현하는 것을 Image Captioning이라고 합니다. One-to-many의 가장 일반적인 예시이며 널리 사용되고 있는 방식입니다. CNN과 RNN을 사용하여 Image를 설명하는 하나의 문장을 만들어 보고자 합니다. 먼저 H*W*3의 이미지가 Input data로 들어옵니다. 이미지는 VGGNet 등의 기법을 사용하여 Features dimension을 만듭니다. RNN층을 통과시켜 이미지를 설명하는 word로 값을 반환하게 됩니다. 하지만 Features dimension이 그림 전체를 설명하고 있기 때문에 그림 전체의 이미지를 한번만 학습하게 됩니다.

이제 CNN 층에서 FC층을 만들지 않고, 3*3*512의 Conv층에서 연산을 마무리 짓는다고 생각해보겠습니다. 3*3의 Features는 이미지를 3*3으로 나누었을 때 각 부분을 의미한다고 생각할 수 있습니다. 이 과정에서 모델은 이제 Weighted Features을 활용하게 됩니다. 각 단어를 예측할 때 9개의 구역으로 나눈 이미지에 가중값을 두어 예측하게 됩니다. 예를 들어, Bird라는 단어를 예측할 때는 그림 가운데 새 부분에 가중값이 높고, Sea를 예측할 때는 그림의 새 부분을 제외한 나머지 부분의 가중값이 높은 형태로 연산이 진행됩니다.
이제 가중값을 어떻게 계산하는지 살펴보겠습니다. 각 은닉층은 위치에 맞는 단어(\(d_n\)), 그리고 하나의 벡터(\(a_n\))를 Output으로 반환합니다. 그림에서 \(a_1\), \(a_2\) ...은 다음 단어를 생성하기 위해 이미지에서 찾고자하는 패턴을 담고있는 벡터입니다. 이 벡터와 CNN층에서 반환된 Features의 벡터와 내적하여 유사도를 추출하여 softmax함수를 적용하면 가중값을 구할 수 있게됩니다.

Visual Question Answering 문제에서 Attention을 어떻게 사용하는가에 대해 살펴보겠습니다. 이미지와 문장을 Input 데이터로 받습니다. CNN을 통해 이미지를 \(a_t\)의 Features를 받고, Attention Map과 함께 답을 도출합니다. 예를 들어, brown이라는 단어를 받았다면 이에 관련된 feature에 가중값을 Attention Map으로 만들어 \(C(I)\)와 결합하여 LSTM 모델에 넘겨주게 됩니다. 마지막 Attention Map 그리고 우측 CNN과의 Attention을 수행하여 이미지에서 어디를 봐야하는가에 대한 답을 찾습니다.
'ML' 카테고리의 다른 글
| Generative Adversarial Network (0) | 2022.12.20 |
|---|---|
| Recurrent Neural Networks (0) | 2022.12.16 |
| Convolution Neural Network (0) | 2022.12.14 |
| Hyper Parameter (0) | 2022.12.12 |
| 신경망(Neural Network) (1) | 2022.12.08 |





댓글 영역