고정 헤더 영역
상세 컨텐츠
본문
- 본 글에서는 딥러닝에 사용되는 몇 가지 하이퍼 파라미터에 대해 간단히 소개합니다.
1. Hyper Parameter
딥러닝을 위한 기반은 여러 가지 있겠지만, 그중 가장 중요하다고 생각하는 몇 가지 개념에 대해 설명하는 글입니다.
Activation Function, Gradient Descent, Learing Rate 등 흔히 하이퍼 파라미터라고 말하는 개념들에 대한 것입니다. 하이퍼 파라메터는 모델 아키텍처와 같이 학습에 지대한 영향을 끼칩니다. 활성화함수를 어떤 함수로 설정하느냐, LR을 얼마로 설정하느냐 등과 같은 하이퍼 파라메터 설정은 학습 속도와 학습 결과에 영향을 끼칩니다.
2. Activation Function

Activaiton Function, 활성화함수라고 하는 이것은 신경망에서 입력을 받아서 출력을 내보내는 기능을 하는 함수입니다. 신경망의 은닉층과 출력층에서 사용하며 뉴런을 활성화하거나 억제되는 기준을 만들어 줍니다.
2.1 Sigmoid And Softmax
가장 먼저 시그모이드 함수에 대해 알아보겠습니다. 시그모이드 함수는 입력을 정규화하여 0과 1 사이의 값을 출력하는 함수입니다. 쉽게 말해 위 그림과 같이 어떤 X를 입력받아 X = 0일 때의 값을 비교하는 함수입니다. 실수 범위의 X를 받아 [0,1]의 확률로 출력해줍니다. 시그모이드의 단점은 기울기가 줄어들어봐야 1/4이라는 점, x > |2| 일 때 기울기가 거의 0에 가까워진다는 점입니다.

소프트맥스 함수는 3개 이상의 카테고리를 분류하기 위해 사용하는 함수입니다. 시그모이드 함수가 주어진 x와 x=0 일 때의 값을 비교하는 함수였다면, 소프트맥스는 모든 값을 비교하여 각 값에 대한 비율(확률)을 찾는 함수이다. 소프트 맥스를 사용하는 이유는 결국 미분이 가능하기 때문입니다. 후술 하겠지만, 각 레이어는 미분이 가능해야 Loss를 통해 가중값를 조정할 수 있기 때문입니다.
2.2 Hyperbolic Tangent
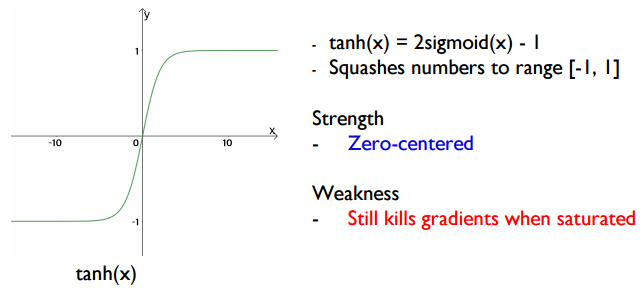
하이퍼볼릭 탄젠트는 시그모이드함수의 변종에 가까운 함수입니다. 2*sgm(x) - 1 = tanh(x)로 나타낼 수 있습니다. 시그모이드 함수의 Zero-centered가 아니라는 단점을 해결한 함수 형태입니다.
2.3 ReLU

ReLU는 딥러닝에서 층을 깊게 쌓을 수 있게 만들어준 장본인인 함수입니다. ReLU함수는 실수의 X를 받아 [0,∞]의 범위로 출력하는 함수입니다. ReLU 함수를 사용하는 주된 이유는 Gradient vanishing 문제를 완화하였기 때문입니다. 가중값를 조정하는 과정에서 층을 깊게 쌓다 보면 가중값의 Gradient가 굉장히 작아지는 문제가 발생합니다. 이 문제는 결국 학습 과정을 느리게 하고 모델이 학습하는 데 방해를 합니다. 하지만 ReLU함수는 x>0에서 Non-zero gradient이기 때문에 이 Gradient vanishing 문제를 완화할 수 있고, 더 빠르고 효과적으로 모델을 학습시킬 수 있습니다.
3. Gradient Descent

일반적인 Gradient descent의 과정을 보면 스마일표시로 가기 위해 수평축과 수직축을 기반으로 움직이게 되는데, 이 과정으로 목표까지 도달하기에는 너무 느립니다.
3.1 Momentum

Momentum 방식은 위의 단점을 해결하기 위해 구상된 방법입니다. 이전 시점의 Gradient descent를 활용하여 더 빠르게 최적화를 할 수 있는 방법입니다. 간단하게 생각하면, 이전 시점의 방향과 이번 시점의 방향이 같으면 더 많이 이동하게 되는 방식입니다. Momentum방식의 또 하나의 특성은 작은 굴곡은 넘어갈 수 있다는 점입니다. 최적점을 찾는 과정에서 이전의 값을 포함하여 이동하기 때문에 오버슈팅을 유발해 Local minima를 넘을 수 있는 것입니다.
3.2 Adam

Adam은 Momentum의 방식인 이전 Gradient descent를 활용하고, RMSProp의 방식인 일종의 정규화를 사용한 방식입니다. 일반적으로 딥러닝 모델을 학습할 때 가장 많이 사용되는 방식이며 빠르고 정확하게 최적화를 실행합니다.
4. Learning Rate

어떤 방식이든 학습률은 아주 중요한 하이퍼파라미터입니다. 학습률에 따라 학습의 진행이 너무 빠르거나, 너무 느려질 수 있어 가장 적당한 학습률을 사용하는 것이 중요합니다.

학습률을 조절하는 방법에는 여러 방법이 있습니다. 먼저, 각 Step마다 학습률을 조절하는 방식이 있습니다. step decay라고 하는 방식인데, 이는 step에 비례해 학습률을 감소시키는 방법입니다. 두 번째는 loss값이 더 이상 감소하지 않는 구간에 도달했을 때 학습률을 감소시키는 방법입니다. 일반적으로 SGD+Momentum은 학습률에 민감하고, Adam은 덜 민감한 것으로 알려져 있습니다. 실제 딥러닝 과정에서 대부분은 Adam을 활용하여 학습을 하게 될 것이고, 학습률을 지정하여 학습을 할 것입니다. 그때 여러 학습률을 사용하여 각 결과를 비교하여 학습률을 조정하는 것도 좋은 방법입니다.
'ML' 카테고리의 다른 글
| Recurrent Neural Networks (0) | 2022.12.16 |
|---|---|
| Convolution Neural Network (0) | 2022.12.14 |
| 신경망(Neural Network) (1) | 2022.12.08 |
| 클러스터링(Clustering) (0) | 2022.12.07 |
| 교차검증(Cross-validation)과 차원축소(Dimension Reduction) (0) | 2022.12.05 |





댓글 영역