고정 헤더 영역
상세 컨텐츠
본문
이번 글에서는 OpenAI, Cohere API의 기본적인 사용방법을 살펴보고, 이전에 구현한 네이버 블로그 / 지식인 검색을 기반으로 질의응답하는 QA봇을 구현합니다. windows 환경에서 docker desktop을 사용하여 docker를 사용하고, 코드 작성 및 ssh 연결은 vscode를 사용합니다.
1. OpenAI API 사용 방법 & 모델 비교
OpenAI는 파이썬으로 다양한 모델을 사용할 수 있도록 API를 제공하고 있습니다. 이번 프로젝트에서 GPT API를 사용하여 질문을 키워드로 변경하는 작업을 할 것입니다.
from openai import OpenAI
# OpenAI 클라이언트를 생성하고 API 키를 설정합니다.
client = OpenAI(api_key="api_key")
# 클라이언트의 채팅 완성 기능을 사용하여 대화를 만듭니다.
completion = client.chat.completions.create(
model="gpt-3.5-turbo-0125", # 사용할 언어 모델을 지정합니다.
messages=[
{"role": "system", "content": "You are a helpful assistant."}, # 시스템 역할 메시지로, AI의 역할을 정의합니다.
{"role": "user", "content": "Hello!"} # 사용자의 메시지입니다.
]
)
# AI의 응답을 출력합니다.
print(completion.choices[0].message)
위 코드는 OpenAI에서 제공하는 공식문서의 Chat 호출 코드입니다. 위 코드를 기반으로 gpt-3.5-turbo 모델과 gpt-4o 모델의 응답을 비교해 보겠습니다.
from openai import OpenAI
llm_client = OpenAI(api_key="api_key")
# 사용자 질문
question = '최근, 한국에 미세먼지가 심해지고 있어. 미세먼지 농도가 높아지는 이유가 뭘까?'
# GPT-3.5-turbo 모델을 사용하여 네이버 검색용 검색 문장 생성
gpt_low_completion = llm_client.chat.completions.create(
model="gpt-3.5-turbo-0125", # 사용할 모델 설정
messages=[
{"role": "system", "content": "당신의 역할은 질문과 관련된 검색 문장을 생성하는 것입니다. 검색 문장은 네이버 검색을 위해 사용되며, 적절한 검색 문장을 사용해야 유저는 올바른 정보를 얻을 수 있습니다. 최대한 짧은 문장으로 표현하되, 검색의 결과를 고려하여 적절한 표현을 선택해주세요."},
{"role": "user", "content": f"{question}"} # 사용자 질문 전달
],
seed=42, # 동일한 결과를 재현하기 위한 시드 값 설정
temperature=0.7, # 출력의 다양성을 조절하는 온도 설정
max_tokens = 128 # 최대 토큰 수 설정
)
# GPT-4 모델을 사용하여 네이버 검색용 검색 문장 생성
gpt_high_completion = llm_client.chat.completions.create(
model="gpt-4o-2024-05-13", # 사용할 모델 설정
messages=[
{"role": "system", "content": "당신의 역할은 질문과 관련된 검색 문장을 생성하는 것입니다. 검색 문장은 구글 검색을 위해 사용되며, 적절한 검색 문장을 사용해야 유저는 올바른 정보를 얻을 수 있습니다. 최대한 짧은 문장으로 표현하되, 검색의 결과를 고려하여 적절한 표현을 선택해주세요."},
{"role": "user", "content": f"{question}"} # 사용자 질문 전달
],
seed=42, # 동일한 결과를 재현하기 위한 시드 값 설정
temperature=0.7, # 출력의 다양성을 조절하는 온도 설정
max_tokens = 128 # 최대 토큰 수 설정
)
# gpt_low_completion의 첫 번째 선택지에서 생성된 검색 문장을 가져와서 따옴표를 제거하고 저장
keyword_low = gpt_low_completion.choices[0].message.content.replace('"','').replace("'","")
# gpt_high_completion의 첫 번째 선택지에서 생성된 검색 문장을 가져와서 따옴표를 제거하고 저장
keyword_high = gpt_high_completion.choices[0].message.content.replace('"','').replace("'","")
# gpt-3.5 모델로 생성된 검색 문장을 출력
print(f'gpt3.5 : {keyword_low}')
# gpt-4 모델로 생성된 검색 문장을 출력
print(f'gpt4 : {keyword_high}')gpt3.5 : 한국의 미세먼지가 심해지는 이유에 대해 알아보려면 대기 오염원이나 기상 조건에 대한 정보를 확인해야 합니다.
gpt4 : 한국 미세먼지 농도 상승 원인
결과를 확인해 보면, gpt-3.5-turbo모델은 검색에 필요한 적절한 형식을 갖추지 못한 결과를 보이고 있습니다. 프롬프트 조정을 통해 이를 일부 해결할 수는 있겠으나, 이보다 더 긴 질문에서 적절한 키워드를 출력하기 위해서는 고성능 모델을 사용할 필요가 있어 보입니다. 또한, 필요한 입력 & 출력 길이가 길지 않고 gpt-4o의 한국어 토큰에 대한 효율이 증가하여 비용의 부담이 크지 않다는 점을 고려하여 이번 프로젝트에서는 gpt-4o를 사용하겠습니다.
보다 구체적인 사용 방법이 궁금하시다면 아래 OpenAI 공식 문서를 참고해 주세요.
https://platform.openai.com/docs/api-reference/chat
2. Cohere API 사용 방법
다음으로 Cohere API를 사용하여 command-r-plus를 사용해 보겠습니다. 해당 모델은 공식적으로 한국어를 지원하며 한 달에 1,000건의 호출을 무료로 사용할 수 있습니다.
import cohere
# Cohere 클라이언트를 생성하고 API 키를 설정
co = cohere.Client("api_key")
# 채팅 요청을 생성하고 응답을 받음
response = co.chat(
chat_history=[
{"role": "USER", "message": "Who discovered gravity?"}, # 사용자 질문
{
"role": "CHATBOT",
"message": "The man who is widely credited with discovering gravity is Sir Isaac Newton",
}, # 챗봇 응답
],
message="What year was he born?", # 새로운 사용자 질문
connectors=[{"id": "web-search"}], # 웹 검색을 위한 커넥터 설정
)
# 응답을 출력
print(response)
위 코드는 Cohere에서 제공하는 공식문서의 Chat 호출 코드입니다. 위 코드를 기반으로 command-r-plus 모델을 테스트해 보겠습니다.
이번 테스트에는 [질문 -> 키워드 추출 -> 검색 -> 검색 결과 추출 -> 프롬프트 입력] 시나리오를 기반으로 예시 코드를 작성해 보겠습니다.
import cohere
import requests
from bs4 import BeautifulSoup
from openai import OpenAI
import numpy as np
import urllib
import time
import json
# GPT와 Cohere API 키를 설정
gpt_client = OpenAI(api_key='gpt_api_key')
crp_client = cohere.Client('crp_api_key')
client_id = 'naver_client_id'
client_secret = 'naver_client_secret'
# 1. 질문
question = '최근, 한국에 미세먼지가 심해지고 있어. 미세먼지 농도가 높아지는 이유가 뭘까?'
# 2. GPT 모델을 사용하여 검색 키워드 생성
gpt_completion = gpt_client.chat.completions.create(
model="gpt-4o-2024-05-13",
messages=[
{"role": "system", "content": "당신의 역할은 질문과 관련된 검색 문장을 생성하는 것입니다. 검색 문장은 구글 검색을 위해 사용되며, 적절한 검색 문장을 사용해야 유저는 올바른 정보를 얻을 수 있습니다. 최대한 짧은 문장으로 표현하되, 검색의 결과를 고려하여 적절한 표현을 선택해주세요."},
{"role": "user", "content": f"{question}"}
],
seed=42,
temperature=0.7,
max_tokens = 1024
)
keyword = gpt_completion.choices[0].message.content.replace('"','').replace("'","")
# 3. 네이버 블로그에서 키워드를 검색
def search_naver_blog(keyword):
encText = urllib.parse.quote(keyword)
url = "https://openapi.naver.com/v1/search/blog?query=" + encText
query_response = urllib.request.Request(url)
query_response.add_header("X-Naver-Client-Id",client_id)
query_response.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(query_response)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
result = json.loads(response_body.decode('utf-8'))
else:
result = "fail"
link_list = []
desc_list = []
# 검색 결과에서 링크와 설명을 추출
for item in result.get('items'):
link_list.append(item['link'])
desc_list.append(item['description'].replace('<b>','').replace('</b>',''))
return result, link_list, desc_list
result, link_list, desc_list = search_naver_blog(keyword)
# 4. 네이버 블로그 링크에서 콘텐츠를 추출
def search_n_contents(link_list):
top_k_content = []
top_k_title = []
for link in link_list:
title, content = search_content(link)
top_k_title.append(title)
# EUC-KR 인코딩을 사용하여 콘텐츠를 디코딩
top_k_content.append(content.encode('euc-kr','ignore').decode('euc-kr'))
time.sleep(np.random.randint(1,4))
return top_k_content, top_k_title
top_k_content, top_k_title = search_n_contents(link_list[:2])
# Cohere API는 documents 변수를 통해 외부 문서를 참조하는 chat template을 제공합니다.
# 콘텐츠와 제목을 [{"title":title, "text":text}, {"title":title, "text":text}, ...] 형식으로 변경
documents = [{"title":title, "text":text} for title, text in zip(top_k_title,top_k_content)]
# 5. Cohere API를 사용하여 질문에 답변 생성
response = crp_client.chat(
message=question,
documents=documents
)
# 답변 출력
print(response.text)미세먼지 농도가 높아지는 주요 원인 중 하나는 대기 중에 산화질소와 황산가스 같은 오염물질이 배출되는 공장, 자동차, 난방 등의 활동으로 인한 대기 오염 때문입니다. 미세먼지는 미립자 크기가 작아 대기 중에 오래 머무를 수 있고, 인체에 해로운 영향을 미칠 수 있습니다.
한국의 2021년 온실가스 배출량은 676.6백만 톤으로, 2020년의 656.2백만 톤에서 증가했습니다. 또한, 2022년 한국의 미세먼지 농도는 18㎍/m³로 나타났습니다.
보다 구체적인 사용 방법이 궁금하시다면 아래 Cohere 공식 문서를 참고해 주세요.
https://docs.cohere.com/reference/chat
3. Gradio 서버 구현
마지막으로 이전 내용을 포함하여 Gradio 서버를 구현합니다. 먼저, 서버 구축을 위한 Docker container를 생성하고 환경을 설정합니다. https://leefromdata.tistory.com/72 를 참고하여 Docker container를 생성하고 conda, cuda 경로 설정을 완료해 주세요.
conda, cuda 경로 설정이 마무리되면 서버에서 사용할 가상환경을 추가하고 필요한 패키지를 설치합니다.
# env_name은 사용하려는 가상환경의 이름, 3.9에는 사용하려는 python 버전을 입력합니다.
conda create -n env_name python=3.9
# 가상환경을 만든 후 활성화합니다.
conda activate env_name
# 필요한 패키지를 설치합니다.
# gradio : 웹 데모에 사용할 gradio 패키지
# openai : OpenAI API 패키지
# cohere : Cohere API 패키지
# FlagEmbedding : bge-m3 모델 사용을 위한 패지키
# beautifulsoup4 : 크롤링(스크래핑) 패키지
pip install -U gradio openai cohere FlagEmbedding beautifulsoup4
Gradio는 웹 데모를 생성하기에 아주 편리한 프로젝트입니다. Text generation, Image generation, STT, TTS 등 다양한 태스크에 대해 쉽게 서비스를 제공할 수 있으며, 허깅페이스의 `Spaces`가 Gradio를 사용하고 있어 쉽게 샘플 확인 가능합니다.
Gradio는 high-level 클래스로 Interface와 ChatInterface를 제공합니다. Interface 싱글턴 대화와 같은 일회성에 적합하고, ChatInterface는 챗봇을 구현할 때 적합합니다.
본문에서는 Interface 클래스를 활용하여 데모를 구현합니다. Interface 클래스는 "fn, inputs, outputs" 3개의 변수를 필수적으로 받습니다.
fn는 웹 데모에서 "generate"와 같은 동작 버튼을 클릭했을 때 입력과 출력 사이의 알고리즘을 의미합니다. 본문에서 fn은 다음과 같은 알고리즘이 필요합니다.
1) [질문 -> 검색 키워드] 변환
2) 블로그 혹은 지식인 본문 크롤링(스크래핑)
3) 질문 + 블로그 본문 혹은 지식인 답변 텍스트를 프롬프트로 하여 command-r-plus에 전달
4) 응답을 반환
inputs는 웹 데모에서 프론트로 나타나는 텍스트 박스 등의 입력창을 의미하며 텍스트, 이미지, 오디오 등 다양한 변수로 입력가능합니다.
outputs는 웹 데모에서 프론트로 나타나는 텍스트 박스 등의 출력창을 의미하며 inputs과 동일하게 텍스트, 이미지, 오디오 등 다양한 변수가 출력될 수 있습니다. 모델의 응답 이외에도 알고리즘 중간의 출력하고자 하는 모든 변수를 사용할 수 있습니다.
inputs, outputs를 위해 gradio에서는 다양한 Components를 제공합니다.
https://www.gradio.app/docs/gradio/components
Gradio Component Docs
Gradio includes pre-built components that can be used as inputs or outputs in your Interface or Blocks with a single line of code.
www.gradio.app
import gradio as gr
import cohere
from FlagEmbedding import BGEM3FlagModel
from datetime import timezone, timedelta
from config import Cohere_config
import naver_blog_scrap
import naver_kin_scrap
import keyword_extract
# 한국 표준시(KST) 설정
KST = timezone(timedelta(hours=9))
# Cohere 클라이언트 생성
crp_client = cohere.Client('api_key')
# 키워드 추출용 모델 이름 설정
keyword_model_name = "gpt-4o-2024-05-13"
# 임베딩 모델 생성 (BGEM3FlagModel 사용)
emb_model = BGEM3FlagModel("BAAI/bge-m3", use_fp16=True, device="cuda")
# 검색 파라미터 설정
search_params = {"metric_type": "COSINE", "params": {}}
# 검색 유형과 프롬프트에 따라 대답 생성
def answering_with_chatcomplate(search_type, prompt):
# 키워드 추출
keyword = keyword_extract.keyword_extract(prompt, keyword_model_name)
# 블로그 검색인 경우
if search_type == 'BLOG':
_, links, descs = naver_blog_scrap.search_naver_blog(keyword)
_, top_k_link = naver_blog_scrap.search_top_k(emb_model, prompt, descs, links, top_k=4, max_length=150)
top_k_contents, top_k_title = naver_blog_scrap.search_n_contents(top_k_link)
final_contents, final_links, _ = naver_blog_scrap.search_top_k(emb_model, prompt, top_k_contents, top_k_link, top_k=2, max_length=512, title_list=top_k_title)
preamble = "당신은 참고 문서에서 질문 관련 내용을 찾아 이를 바탕으로 질문에 대답하는 AI 모델입니다. 참고 문서로 네이버 블로그 글이 주어지며, 이는 질문과 관련있는 내용으로 이루어졌습니다. 질문과 참고 문서를 잘 읽고 올바른 대답을 하길 바랍니다. 만약 참고 문서가 질문과 연관이 없다면 `연관성이 부족한 참고문서입니다. 응답할 수 없습니다.`라고 대답하세요."
# 지식인 검색인 경우
elif search_type == 'KIN':
_, _, links, descs = naver_kin_scrap.search_naver_kin(keyword)
_, final_links = naver_kin_scrap.search_top_k(emb_model, prompt, descs, links, top_k=2, max_length=150)
top_k_content = naver_kin_scrap.search_n_contents(top_k_link, top_k=2)
final_contents = naver_kin_scrap.content_top_k_by_embedding(emb_model, prompt, top_k_content, top_k=2, max_length=512)
preamble = "당신은 참고 문서에서 질문 관련 내용을 찾아 이를 바탕으로 질문에 대답하는 AI 모델입니다. 참고 문서로 네이버 지식인 글이 주어지며, 이는 질문과 관련있는 내용으로 이루어졌습니다. 질문과 참고 문서를 잘 읽고 올바른 대답을 하길 바랍니다. 만약 참고 문서가 질문과 연관이 없다면 `연관성이 부족한 참고문서입니다. 응답할 수 없습니다.`라고 대답하세요."
# 질문과 유사도가 가장 높은 2개의 최종 문서 설정
documents_1 = [{"title": 'title 1', "text": final_contents[0]}]
documents_2 = [{"title": 'title 2', "text": final_contents[1]}]
# 첫 번째 응답 생성
output_1 = crp_client.chat(
message=prompt,
documents=documents_1,
preamble=preamble,
prompt_truncation='AUTO'
)
# 두 번째 응답 생성
output_2 = crp_client.chat(
message=prompt,
documents=documents_2,
preamble=preamble,
prompt_truncation='AUTO'
)
# 결과 반환 : 응답-1, 응답-2, 검색 키워드, 참조문서 링크-1, 참조문서 링크-2
return output_1.text, output_2.text, keyword, final_links[0], final_links[1]
# 검색 유형 설정
search_type = ['BLOG', 'KIN']
# Gradio 인터페이스 설정
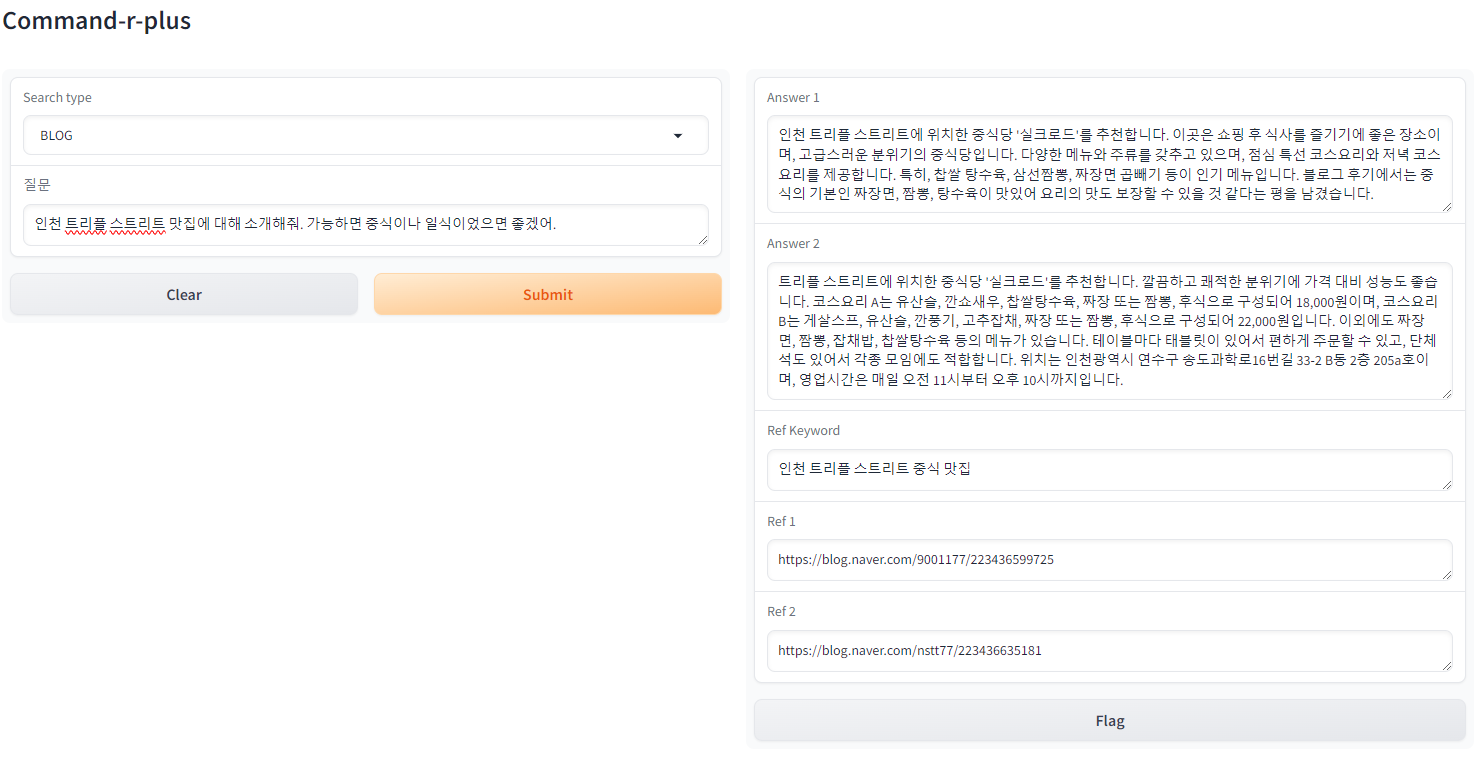
demo = gr.Interface(
fn=answering_with_chatcomplate,
title='Command-r-plus',
inputs=[gr.Dropdown(search_type, label='Search type'), gr.Textbox(label="질문")],
outputs=[gr.Textbox(label="Answer 1"), gr.Textbox(label="Answer 2"), gr.Textbox(label="Ref Keyword"), gr.Textbox(label="Ref 1"), gr.Textbox(label="Ref 2")],
)
if __name__ == "__main__":
demo.launch(server_name="0.0.0.0", server_port=7860) # share=True
4. Gradio 동작 확인
마지막으로 구현한 Gradio가 문제없이 작동하는지 웹에서 확인합니다. http://127.0.0.1:7860로 Gradio 웹 데모에 접속할 수 있습니다.
'NLP' 카테고리의 다른 글
| LLM with Naver API - 크롤러 구현 (0) | 2024.05.17 |
|---|---|
| LLM with Naver API (0) | 2024.05.16 |
| LLM with RAG - Gradio server (0) | 2024.05.09 |
| LLM with RAG - LLM server (0) | 2024.05.08 |
| LLM with RAG - milvus server (0) | 2024.05.07 |





댓글 영역