고정 헤더 영역
상세 컨텐츠
본문
논문 주소 :
LoRA - https://arxiv.org/abs/2106.09685
VeRA - https://arxiv.org/abs/2305.03695
이 논문은 LLM을 Fine-tune하는데 있어, 효과적인 방법을 소개하는 논문입니다.
두 방법 모두 학습해야 할 파라미터의 수를 조절하여 효과적인 학습을 가능케 합니다. 그럼에도 불구하고 전체 학습 파라미터를 학습하는 것과 비슷한 수준의 효과를 보이고 있어 보편적으로 사용되고 있습니다.
본 글에서는 LoRA와 VeRA의 특징 및 주요 내용을 정리하고 있습니다. 각 논문에는 더 구체적인 내용이 담겨있으니, 시간이 있는 경우 읽어보기실 추천 드립니다.
1. LoRA : LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS
Key contributions
본 연구의 Key contribution은 self-attention layer를 Decomposition하여 효과적인 학습 방법을 고안한 것입니다. 이 방법에서 오는 장점은 다음과 같습니다.
먼저, 이 방법은 학습 시 기존보다 작은 GPU RAM을 요구합니다. LoRA 방법으로 학습할 경우, 메모리 요구량이 1/3 수준으로 감소합니다.
두 번째로, 특정 태스크에 대해 작은 LoRA Module을 저장하면 됩니다. 기존 방법대로 Full-finetune을 한다면 각 태스크 별로 모든 파라미터를 개별로 저장해야 했습니다. 하지만 LoRA 방법으로 학습하면 하나의 전체 파라미터와 개별 LoRA Module만 저장하면 됩니다.
세 번째로, LoRA는 prefix-tuning과 같은 이전에 등장한 방법론과 orthogonal한 방법입니다. 이에 따라 다른 방법론들과 결합하여 사용할 수 있습니다.
마지막으로 추론 레이턴시가 증가하지 않습니다. LoRA 방법론이 등장하기 이전에 효과적인 학습 방법론인 Adapter는 self-attention layer 위에 하나의 레이어를 더 만들어 추론 시 레이턴시가 증가했습니다. 하지만, LoRA 방법은 학습 시에만 LoRA Module을 사용하고, 추론 시에는 기존의 파라미터의 수 만큼만 사용하기 때문에 추론 레이턴시가 증가하지 않습니다.
1) LoRA

LoRA는 다음 그림과 같은 방식을 사용합니다. 기존에 사전학습된 Pretrained Weights(d*d) 행렬을 A(d*r)과 B(r*d) 행렬로 분해하여 우측 2개의 파라미터만 학습합니다. 학습이 끝나 후, 기존의 Pretrained Weights와 AB 행렬을 결합하기 때문에 추론 레이턴시의 변화가 없습니다.
본 연구에서 A의 초기 가중치는 random Gaussian initialization을 적용하였고, B는 0 행렬을 적용했습니다. LoRA 모듈의 하이퍼 파라메터로 α, r가 있으며 α는 기존 방식의 학습률, r은 분해할 행렬의 차원으로 이해하면 쉽게 이해할 수 있습니다.
2) Inference latency

LoRA 방법의 장점 중 하나는 추론 시에 레이턴시가 기존 Full-finetune한 모델과 동일하다는 것입니다. 이전에 등장한 Adapter을 적용한 방법은 학습 파라미터의 개수에 따라 추론 레이턴시가 증가하는 경향을 보입니다. 추론 속도는 모델을 서비스할 때 중요한 요소로 여겨지기 때문에 LoRA의 이러한 장점은 서비스 측면에서 굉장히 효율적이라고 볼 수 있습니다.
3) GPU Requirement
LLM의 크기가 증가함에 따라 학습하는데 필요한 GPU의 사양이 높아지고 있으며 이에 따라 비용이 크게 증가하고 있습니다. 메타 등에서 공개한 오픈소스 모델을 각 태스크에 맞추어 Full-finetune 할 때 다소 높은 비용이 요구됩니다. LoRA는 메모리 측면에서 GPU의 요구량을 상당히 낮춰줍니다.
HuggingFace의 `can-it-run-llm` space를 통해 Full-finetune에 필요한 GPU 수준과 LoRA를 적용한 경우 필요한 GPU 수준을 비교할 수 있습니다.

위 그림을 확인해보면, Full-Finetune에 필요한 GPU의 개수, 요구되는 메모리 총량과 LoRA를 적용했을 때 필요한 GPU의 개수, 요구되는 메모리 총량을 비교할 수 있습니다. LoRA의 방식이 Full-Finetune 방식에 비해 약 1/3의 메모리가 사용되는 것을 확인할 수 있습니다.
4) Empirical Experiments
본 연구에서는 RoBERTa, DeBERTa, GPT-2, GPT-3에 다양한 학습 방식을 적용하여 여러 데이터셋에 대해 성능을 비교하였습니다.

위 실험은 인코더 모델에 Full-fineutne, BitFit, Adapter, LoRA의 학습 방식을 적용한 결과를 보이고 있습니다. 각 학습 방식에 대한 내용은 논문에 기재되어 있습니다.
LoRA 학습 방법은 모든 모델에서 Full-finetune 방식 뿐만 아니라 이전에 등장한 효율적인 학습 방법보다 높은 평균 성능을 보였습니다.

다음으로 디코더 모델인 GPT-2 M, L 모델에서도 기존 방법보다 높은 성능을 보인 것을 확인할 수 있습니다.

GPT-3 모델에 적용한 결과 역시, 기존의 방법보다 높은 성능을 보인 것을 확인할 수 있습니다.
연구진들은 대부분의 모델에서 LoRA 학습 방법으로 학습한 경우, 다른 학습 방법에 비해 뒤쳐지지 않는다는 사실을 실험적으로 입증했습니다.
2. VERA : VECTOR-BASED RANDOM MATRIX ADAPTATION
Key contributions
본 연구의 Key contribution은 LoRA 방법보다 더 적은 파라미터를 사용하여 학습하며, 추론 레이턴시 역시 증가하지 않는 새로운 학습 방법을 고안한 것입니다. 연구진들은 더 적은 파라미터를 사용하였지만 실험적인 결과로 비슷한 성능을 확인하였습니다.
연구진들은 LoRA 연구와 동일하게, NLU와 NLG 벤치마크를 사용하여 이전 학습 방법의 성능과 VeRA 학습 방법의 성능을 비교하였습니다. 또한 ablation study를 통해 학습에 사용되는 각 컴포넌트(하이퍼 파라미터)에 대해 연구한 점입니다.
1) VeRA
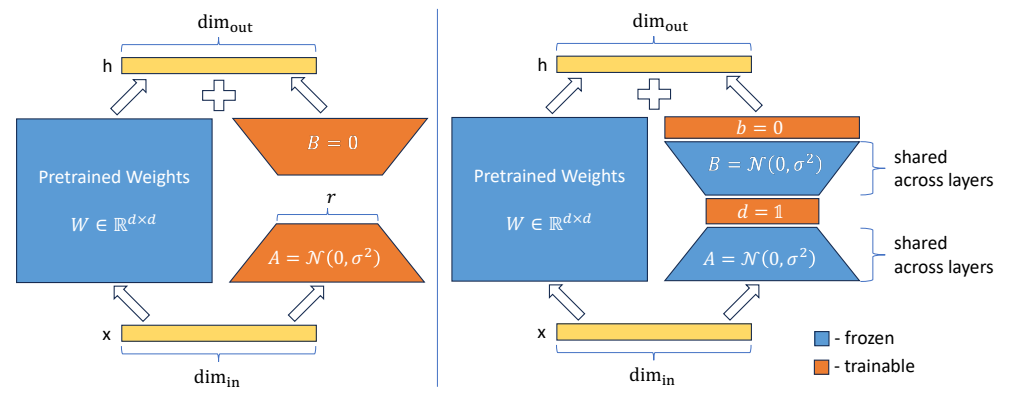
LoRA와 VeRA의 차이는 다음 그림을 통해 확인할 수 있습니다. Pretrained Weights을 분해하여 2개의 '행렬'을 학습했던 LoRA 방식과 달리, VeRA는 Pretrained Weights을 분해하여 2개의 `행렬`과 2개의 `벡터`로 분해하여 `벡터`만 학습하여 더 적은 학습 파라미터를 사용했습니다.
연구진들은 이 방법을 `Vector-based Random Matrix Adaptation`이라는 새로운 학습 방법으로 소개하였습니다.
이 방법의 장점은 LoRA보다 더 적은 학습 파라미터를 사용하는 것과, 모델을 저장할 때 A,B에 대한 random seed, 그리고 b, d 두 개의 벡터만 저장하여 효과적인 메모리 사용을 할 수 있다는 것입니다.
또한, LoRA와 동일하게 학습이 끝난 후 low-rank 행렬을 Pretrained Weights와 결합하여 추론 레이턴시에는 변화가 없습니다.
2) LoRA vs VeRA
연구진들은 VeRA 학습 방법의 효율적인 메모리 사용을 보여주기 위해 LoRA와 비교하고 있습니다. VeRA는 LoRA에 비해 파라미터 사용이 절반 이하로 사용하고, rank의 크기에 따라 파라미터의 절약 수준이 증가합니다.

위 표는 RoBERTA와 GPT-3에 대해 LoRA, VeRA 학습 방법으로 학습했을 때 사용하는 학습 파라미터의 개수와 이에 대응되는 메모리 수준입니다. rank가 증가할수록 감소하는 학습 파라미터의 수는 극단적으로 감소하게 됩니다.
3) Experiments

연구진들은 먼저 NLU 태스크에 학습 방법 별 성능을 비교하기 위해 RoBERTa 모델에 그림과 같은 학습 방법을 적용하여 성능을 평가했습니다. RoBERTa-BASE 모델에서는 LoRA 학습 방법이 가장 높은 평균 성능을 보였고, LARGE 모델에서는 LoRA와 VeRA가 동일하게 가장 높은 성능을 보였습니다.

다음으로 NLG 태스크에 대해 성능을 비교하기 위해 GPT-2 모델에 그림과 같은 학습 방법을 적용하여 성능을 평가했습니다. 평가표를 보면, LoRA와 VeRA 학습 방법이 가장 상위의 성능을 보이고 있습니다.

연구진들은 마지막으로 메타의 Llama-2 7B 모델에 대해 LoRA와 VeRA 학습 방법으로 Instruction tuning을 했을 때, 어떤 방법이 더 높은 성능을 보이는지 확인하기 위해 다음 실험을 진행했습니다.
먼저, 메타에서 공개한 Llama-2 7B 모델에 Alpaca cleaned version 데이터 셋을 사용하여 instruction tuning을 진행했습니다. Rank는 64를 사용했으며 모든 linear layer에 대해 적용하였고, 양자화를 통해 single GPU를 사용하여 학습했습니다.
학습이 끝난 후 두 모델에 대해 80개의 질문에 대한 응답을 생성했습니다. 각 응답은 GPT-4에 의해 평가되었고, 10점 척도로 평가되었습니다.
결과적으로, LoRA보다 VeRA가 소폭 높은 점수를 얻은 것을 확인할 수 있습니다. 연구진들은 학습 파라미터의 수가 100배 이상 차이나는 수준에서 유의미한 결과를 보였다고 말하고 있습니다.
'Paper' 카테고리의 다른 글
| Large language models encode clinical knowledge (1) | 2023.11.03 |
|---|





댓글 영역