고정 헤더 영역
상세 컨텐츠
본문
논문 주소 : https://doi.org/10.1038/s41586-023-06291-2
이 논문은 LLM이 의료 지식을 이해하고 적절한 대답을 생성할 수 있는가에 대해 연구한 논문입니다. 구글 리서치가 주가 되어 작성된 논문이며 2023년 6월에 Nature에 억셉되어 2023년 7월에 출간되었습니다.
Key contributions
본 연구의 key contributions은 1. Medical QA dataset의 개발, 2. MedQA 등의 여러 의료 관련 벤치마크에서 Sota를 달성 , 3. Human evaluation framework의 개발 한 것입니다.
Research contents
1. Medical QA dataset development
연구진들은 Medical exam, Reseach 데이터를 포함한 MultiMedQA 벤치마크를 개발했습니다. 이 데이터셋은 총 7개의 기존 데이터셋 - MedQa, MedMCQA, PubMedQA, MMLU clinical topics, LiveQA, MedicationQA, HealthSearchQA -을 결합하였으며 Multiple-choice answer 형식과 Medical question with long-form answer 형식을 포함하고 있습니다. 데이터는 모두 영어로 구성되어 있으며 각 데이터셋 구성은 아래와 같습니다.
| 데이터셋 명 | 특징 | Development size | Test size |
| MedQA(USMLE) |
USMLE-style QA dataset with four or five possible answer
|
11,450 | 1,273 |
| MedMCQA |
Four-option multiple-choice question, 2400 heathcare topics and 21 medical subjects
|
187,000 | 6,100 |
| PubMedQA |
1000 expert-labelled question-answer pair, Question + Context +
Answer pair |
500 | 500 |
| MMLU clinical |
Selected the subtask most relevant to medical knowledge
|
Differences by task | |
| LiveQA |
Reference answer from trusted sources such as National Institute of Health web site
|
634 | 104 |
| MedicationQA |
Commonly asked consumer question about medications,
annotations corresponding to drug focus and interactions. |
NA | 674 |
| HealthSearchQA |
Curated using seed medical conditions and their associated
symptoms(Only Question) |
3,173 | |
2. Demonstrate state-of-the-art performance on the MedQA, MedMCQA, PubMedQA, MMLU clinical topics
연구진들은 Pretrained-LLM인 PaLM에 Instruction tuning을 하여 Flan-PaLM을 개발하였습니다. Flan-PaLM은 다양한 측면에서 성능이 평가되었습니다. 먼저 연구자들은 Flan-PaLM을 평가하는데 먼저 Medical Question Answering task를 채택했습니다. 프롬프트 방법으로는 few-shot, CoT, Self-consistency 방법을 사용했습니다.

2-2. Ablation Study
연구진들은 결과에 대해 더 깊이 이해하고 성능의 핵심 요소가 무엇인지 판단하기 위해 MedQa, MedMCQA, PubMedQA에 대해 여러 ablation study를 진행했습니다.
1) Instruction tuning
모든 모델 사이즈에서 Flan-PaLM은 베이스라인은 PaLM의 성능을 능가했습니다. 모두 few-shot 프롬프트를 사용했으며
정리된 결과는 아래와 같습니다.

2) Scaling effect
연구진들은 모델 사이즈의 크기에 따라 모델의 성능이 증가한다는 것을 보였습니다. 8B부터 540B까지 모델의 크기가 증가함에 따라 모델은 최대 2배의 성능 증가를 보였습니다.

3) COT prompting
연구진들은 COT 기법이 이번 연구에서 성능향상을 보이지 못했다고 확인했습니다. 이들은 COT 방식이 여러 가능한 reasoning path를 가지고 있고, 이 중 하나를 고르는 것은 항상 가장 정확한 정답을 내놓는 것이 아니기 때문이라고 보았습니다. 또한 COT 프롬프팅이 어떤 문제를 해결하기 위한 도움(꾐)을 주는 데 효과적일뿐, 새로운 지식을 추가하는 방식이 아니라는 것을 이야기합니다.
4) Self-consistency
연구진들은 COT 기법을 적용할 때, 여러 가능한 추론 중 하나만을 출력하기 때문에 성능의 향상으로 이루어지지 않는다고 판단했습니다. 이에 따라, 다양한 답변을 생성한 후 다수결을 통해 가장 많이 출력된 정답을 마지막 정답으로 판단했습니다. MedQA와 MedMCQA에는 성능의 향상이 있었지만, PubMedQA에서는 오히려 성능이 감소했습니다
.
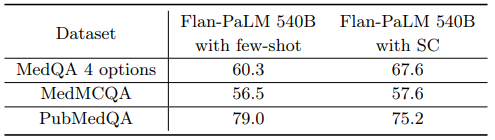
5) Uncertainty and selective prediction
의학 분야에서 실제 세상의 적용을 위해서는 모델의 응답이 실패하는 경우, 즉 중요한 정보를 빠뜨리거나 잘못된 정보를 제공하는 경우에는 생성된 정보를 전달하지 않아야 합니다. 대신, 정확한 정보를 생성할 때 까지 기다리는 방식으로 이를 지연할 수 있습니다. 연구진들은 이를 위해 LLM이 생성한 문장의 uncertainty를 측정하여 특정 수치의 uncertainty를 넘어설 때 까지 응답을 대기하는 방법을 연구했습니다.
self-consistency로 주어진 문장들을 매칭하는 디코드의 개수를 uncertainty의 측정값으로 사용하여 연구를 진행한 결과 MedQA 데이터셋에 대해 82.5%까지 정확도의 향상을 보였습니다. 이를 통해, 연구진들은 모델이 의료 분야에서 그들의 지식에 대해 uncertainty를 인코딩하는 능력이 있는 것으로 보여진다고 판단했습니다.
3. Human evaluation - Clinician
연구진들은 기존에 모델을 평가하는 방식인 단순히 정답지 중 하나를 선택하는 방식은 모델의 성능을 정확히 평가하기 어렵다고 판단했습니다. 이런 평가 방식은 실제로 모델이 유저에게 도움을 줄 수 있는지, 혹은 Hallucination이 없는지 등을 성능적으로 판단하기 어렵다고 생각했습니다.
이에 따라 연구진들은 새로운 평가 방식인 Human evaluaion을 도입하여 Flan-PaLM의 성능을 측정했습니다. 평가에는 총 140개의 질문이 사용되었으며 HealthSearchQA에서 100개, LiveQa에서 20개, MedicationQA 20개를 선택했습니다. 이후 3명의 패널에게 적절한 대답 작성을 요청하고, Flan-PaLM을 사용하여 대답을 생성했습니다.
결과적으로 이 평가 방식에서 Flan-PaLM은 몇 가지 문제를 드러내며 좋지 않은 성능을 보였습니다. 이에 따라 연구진들은 의학 도메인의 데이터에 대해 Instruction prompt tuning을 진행하여 Med-PaLM 모델을 새로이 개발했습니다.
Med-PaLM을 학습하는데 사용된 데이터는 다음과 같은 방식으로 생성되었습니다. 먼저, MultiMedQA 데이터 셋에서 free-response dataset에서 샘플을 선택한 후, 5명의 패널에게 정답을 요청했습니다. 그 후 모델 학습에 적절하지 못한 질문/정답 페어를 제거하여 결과적으로 총 65개의 데이터를 생성했습니다.

이전에 생성한 140개의 질문에 대해 Med-PaLM의 대답을 생성한 후, 평가항목에 따른 분석을 진행했습니다.
3.1 Scientific consensus
세 대답이 의학, 과학 커뮤니티의 의견을 얼마나 잘 수용하고 따르고 있는지를 평가했습니다. Flan-PaLM은 61.9%, Med-PaLM은 92.6%, Clinician은 92.9%를 보였습니다. 연구진들은 이를 통해 Generic한 instruction tuning이 과학적, 의학적 기반의 대답을 생성하기에 충분하지 않다는 것을 의미한다고 보았습니다. Med-PaLM의 높은 성능을 통해 연구진들은 특정 분야의 샘플만을 사용하여 학습을 하는 경우, 그 분야에 대해 Alignment에 좋은 효과를 갖는다고 판단했습니다.
**첨언으로 연구진들은 LLM의 학습에 있어 다양한 데이터셋을 사용하기 때문에, 과거의 지식(예를 들어, 1900년대의 잘못된 의학 지식)을 학습할 가능성이 있다고 보았습니다.

3.2 Medical comprehension, Knowledge retrieval, Reasoning capability
연구진들은 모델이 의학적 이해를 기반으로 대답을 생성하고 있는지, 지식을 정확히 검색하는지, 추론 능력을 보유하고 있는지를 테스트했습니다. 각 대답은 세 종류의 학목에 대해 정확한 내용과 부정확한 내용이 동시에 담길 수 있는 여지가 있기 때문에, 연구진들은 Correct와 Incorrect로 나누어 평가했습니다.

3.3 Incorrect content
연구진들은 각 대답이 부정확한 정보를 내포한 정도를 측정했습니다. 의학적으로 중요한 정보가 잘못되었거나, 중요하지는 않지만 의학적인 정보가 잘못된 경우를 체크하는 방식으로 평가했습니다. 이 경우, 유일하게 Flan-PaLM이 Med-PaLM보다 좋은 평가를 받았는데, 연구진들이 생각하기로 이는 Med-PaLM이 더 긴 문장을 생성하기 때문에, 부정확한 정보를 포함할 가능성이 높을 것이라고 판단했습니다.

3.4 Missing content
연구진들은 각 대답이 의학 정보를 놓쳤는지에 대해 측정했습니다. 위와 마찬가지로, 의학적으로 중요한 정보가 빠졌는지, 혹은 중요하지는 않지만 필요한 의학적 정보가 빠졌는지를 체크했습니다.

3.5 Extent and Likelihood of possible harm
연구진들은 각 대답이 사람을 얼마나 위험하게 만들 수 있는 대답인지, 또 가능성이 얼마나 높은지를 평가했습니다. 평가자가 선택할 수 있는 위험성 수준은 [사망, 혹은 심각한 부상], [중등도의 피해, 가벼운 피해], [피해가 없음] 이며 이에 따라 평가자의 주관이 들어갈 가능성이 있음을 인지해야합니다.

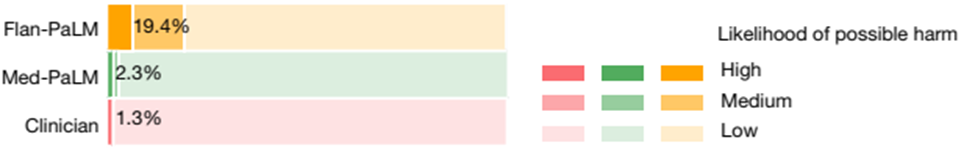
3.6 Bias for medical demographics
마지막으로, 각 대답이 특정 인구에 대해 부정확한지, 혹은 부적당한 내용을 내포하고 있는지 평가했습니다. 이 평가에서 대부분의 질문은 중립적으로 구성되어 있고, 특정 인구 통계 추론을 포함하지 않아 제한적이며 잠재적인 피해, 공평성 또는 평등성의 포괄적인 평가로 기능하지는 않습니다.

4. Human evaluation - User
다음으로 연구진들은 일반 유저에게 모델이 생성한 대답의 평가를 요청했습니다. 유저 측면에서는 각 대답이 질문을 얼마나 이해하고 있으며, 대답이 실제로 유저에게 도움을 주고 있는지를 평가했습니다.

5. Limitation
연구진들은 마지막으로 이 연구가 가지고 있는 한계에 대해 논의했습니다. 먼저, 그들이 개발한 데이터셋인 MultiMedQA 벤치마크는 폭넓고 다양한 종류의 데이터를 포함하고 있지만, 생물학과 같은 더 다양한 의학 및 과학를 포함해야 하고 다양한 형식을 포함해야 한다고 말하고 있습니다.
또한 의학 환경에서 주요 챌린지는 환자로부터 정보를 이끌어내고, 그들의 정보를 종합하여 assessment와 plan으로 이어지는 것입니다. 하지만, 지금과같은 벤치마크는 근본적으로 이보다는 쉬운 조건에서 진행된다는 한계를 갖고 있다고 말합니다. 이에 따라 실제 세상의 Workflow를 따르는 벤치마크를 개발하는 것이 중요하다고 말하고 있습니다.
이번 연구의 Human evaluation framework는 파일럿 방식이며 근본적으로 주관이 많이 들어가는 방식이기 때문에 완벽한 방식이 아니라고 판단하고 있습니다. 또한 Clinical, scientific consensus는 시간에 따라 변화하는 특성을 가지고 있으며 건강, 질병, 생리학의 이해를 반영하는 등 다양한 환경에 영향을 받을수 밖에 없다고 생각하고 있습니다. 위험도의 수준이나 가능성 역시 평가자의 환경, 문화에 따라 편차가 크고, 평가 인원 역시 소수이기 때문에 편차가 크다는 한계가 있다고 말합니다.
'Paper' 카테고리의 다른 글
| LoRA & VeRA (0) | 2023.11.17 |
|---|





댓글 영역