Transformer
- Transformer는 Attention 기반으로 설계된 모델 아키텍처입니다.
- 자연어 처리와 컴퓨터 비전 영역에서 다양한 변형으로 사용되고 있으며 현대 AI의 기반이 되는 아키텍처입니다.
1. 소개
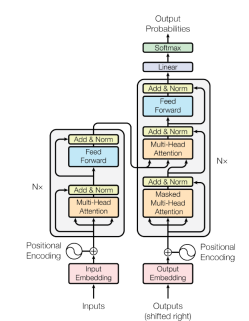
`Attention is all you need` 논문에서 Transfomer가 소개된 이후 많은 변형이 등장하였고, Transformer의 Encoder/Decoder Block은 여전히 많이 사용되고 있습니다. 오늘은 Transformer의 입력부터 출력까지 어떤 연산을 거치며, 각 연산의 의미를 생각해보겠습니다.
기본적으로 Transformer는 위 그림과 같은 구조를 가지고 있습니다. Transformer는 크게 Encoder Block과 Decoder Block으로 구성되어 있습니다. 세부 구조에는 Positional Encoding, Multi-Head Attention 등의 세부 구조가 있고, 이에 대해 자세히 다루어 보고자 합니다. 그 중 가장 먼저 Embedding과 Positional Encoding에 대해 살펴보겠습니다.
2. Embedding and Positional Encoding
임베딩은 컴퓨터가 자연어를 인식할 수 없으니, 컴퓨터가 인식할 수 있는 형태로 바꿔주는 과정이라고 생각하면 됩니다. 예를 들어, "I want to go home" 문장을 [0.2231, 0.5512, 1.2441 ~] 의 형태인 벡터로 바꿔주는 연산입니다.
다음으로 Positional Encoding에 대해 살펴보겠습니다. 이것은 문장 내 단어의 위치와 관련된 연산입니다. 자세한 내용은 아래 그림을 보며 설명하겠습니다.

Transformer의 Attention은 RNNs와 다르게 단어의 순서를 인지하지 못합니다. 예를 들어, 'I go home'이라는 문장과 'go I home' 두 문장은 같은 의미를 갖고, 동일한 임베딩을 갖게 됩니다. 보통 단어의 순서가 다르면 문장은 다른 의미를 가지는 경우가 많으니 순서를 고려하지 못하는 것은 큰 문제가 될 가능성이 있습니다. 이에 Transformer 모델에서는 Positional Encoding을 사용합니다. 각 시점에 따라 단어의 임베딩에 어떤 표식을 추가해주는 방법입니다. Transformer는 Sine 함수와 Cosine함수를 사용하였습니다.
3. Attention

위 그림은 일반적인 RNN 구조입니다. RNN구조에서 문제가 된 부분은 Gradient Vanishing입니다. 가장 먼저 입력된 'I'에 담긴 정보가 RNN 모듈을 통과하면서 점차 희미해져 문장의 뒷 부분으로 갈 수록 앞의 단어의 정보를 잃어버리게 됩니다. 이 구조적 문제를 해결하기 위해 LSTM, GRU와 같은 변형 모델이 등장했지만 여전히 Gradient Vanishing은 RNN의 큰 문제로 남았습니다.
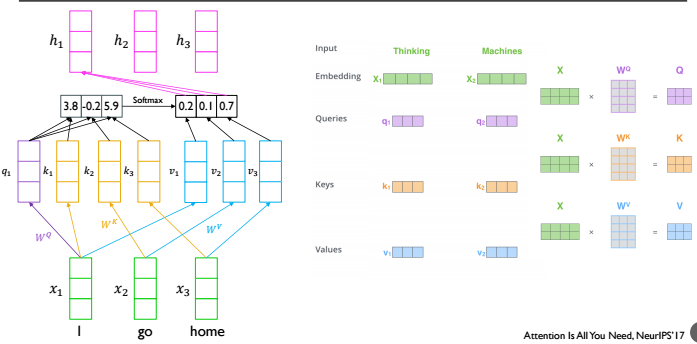
Self-Attention도 Gradient Vanishing문제를 해결하기 위해 탄생하였습니다. Attention의 과정은 다음 그림과 같습니다. \(x_1\) 'Thinking', \(x_2\) 'Machines'이라는 두 개의 단어가 입력 데이터로 들어와 임베딩되어 벡터로 만들어집니다. 임베딩된 벡터와 각 \(W^Q, W^K, W^V\)를 선형결합하여 Q, K, V를 구합니다.
이 때 Query 벡터는 각 입력 벡터에 대한 Query입니다. 유사도를 구하는데 사용하는 벡터가 Key벡터이고, softmax가 적용된 유사도와 곱하여 출력 벡터를 만들기 위해 사용하는 벡터가 Value 벡터입니다. 다시 말해 \(x_i\)에 대해 \(q_i\)를 구하고 K와 선형결합하여 유사도를 구한 후, Softmax를 취한 벡터와 Value벡터간 선형결합으로 만들어진 것이 출력벡터입니다. 이런 방식으로 하여금 Time step에 상관 없이 정보의 손실을 막을 수 있게 됩니다.

위의 그림의 식으로 표현하면 다음과 같습니다. q는 Query, K는 Key, V는 Value입니다. \(q\)와 \(k_i\)의 내적을 소프트맥스 함수를 적용하여 만든 벡터와 \(v_i\)를 곱합니다.
그림의 아랫 부분은 이 과정에 대한 하이레벨의 설명입니다. 첫 번째 벡터는 Query작용을 위한 벡터입니다. 두 번째는 K의 벡터의 Transpose작용을 한 벡터입니다. 세 번째는 V의 벡터입니다. Query와 Key를 곱하여 만든 행렬에 Row-wise softmax연산을 한 후 다시 Value를 곱합니다. 이러한 연산이 끝나면 마지막 그림과 같은 차원의 행렬로 변환됩니다.

그러나 이 연산식에는 한 가지 문제가 있습니다. \(QK^T\)에 단순히 softmax연산을 하면 값이 클수록 벡터 내의 값들의 차이가 커집니다. 예를 들어 [1,2,3] 벡터에 softmax를 취한 결과보다 [100,200,300] 벡터에 softmax를 취한 결과가 벡터 내 값 간의 차이가 훨씬 크다는것을 알 수 있습니다. 이런 문제를 해소하기 위해 \(QK^T\)를 \(d_k\)로 나누어 벡터 내 값 간의 차이를 줄였습니다. 하지만 이 과정에서 \(d_k\)가 커질수록 \(q^Tk\)의 분포도 커지기 때문에 softmax연산의 결과 벡터의 분포는 더욱 커지는 문제가 발생합니다. 이 문제를 해결하기 위해 \(d_k\)의 루트를 씌워 scaled해주는 방법을 사용합니다.

`Attention is All you Need`에서는 Attention을 활용하여 Multi-head Attention을 구현했습니다. 여러 Attention을 병렬처리하고, 각 Attention의 head를 concat하여 사용하는 것입니다. 쉽게 생각하면 Attention을 여러개 엮은 구현체입니다.


그림과 같이 입력 문장 X를 임베딩한 벡터에 대해 여러 개의 Attention을 병렬적으로 수행합니다. 연산을 통해 나온\(Z_i\)를 Concat하고 \(W^0\)와 연산하여 Z를 얻습니다.
4. Encoder Block in Transformer

다음은 Transformer을 구성하는 Encoder Block입니다. 각 Block은 Multi-head Attention과 Feed Forward, 그리고 Normalization으로 구성되어 있습니다. Block을 구성하는 Multi-head Attention은 위에서 먼저 설명을 했으니, 다음으로 Feed Forward와 Normalization에 대해 설명하겠습니다.

Normalizaion은 두 가지 단계로 이루어져 있습니다. 먼저, Multi-Head Attention/Feed Forward 연산 후 나온 벡터와 입력 벡터(Multi-Head Attention/Feed Forward를 거치지 않은 기존의 입력 벡터)를 더합니다. 연산이 끝난 벡터에 대해 평균은 0, 분산은 1이 되도록 Normalize을 합니다. 그 다음 노드(벡터 내 개별 값) 별로 \(y = ax + b\)연산을 하여 마지막 최종 벡터를 만듭니다. 이 때 \(y = ax + b\)에서 \(a\)와 \(b\)는 학습에 의해 최적화된 값으로 정해집니다.

Feed Forward는 단순한 Fully Connected 연산을 합니다. FC연산 이후 다시 동일한 Normalization연산이 이루어집니다.
5. Decoder Block in Transformer

지금까지 Transformer의 Encoder Block을 살펴보았습니다. 다음으로 Decoder Block를 살펴보겠습니다. Decoder Block의 구성은 Encoder Block와 비슷합니다. Decoder Block은 크게 Masked Multi-Head Attention, Multi-Head Attention, Feed Forward, Normalization으로 구성되어 있으며 Decoder Block의 입력은 이전 time step의 output이 입력됩니다.
Decoder Block의 학습 과정에서는 이전 time step의 output이 아닌 실제 정답 문장이 입력되고, 각 time step의 단어를 예측하도록 학습됩니다. 문장 전체가 입력되기 때문에 모델은 현재 시점보다 뒷 시점의 단어를 참고할 여지가 생깁니다. 이 문제를 해결하기 위해 Look-Ahead Mask가 적용된 Masked Multi-Head Attention을 사용합니다.

Masked Multi-Head Attention은 Decoder Block에서 Attention을 적용할 때, 현재 단어보다 뒤에 있는 단어에 Attention을 적용하는 것을 방지합니다. 예를 들어 '<sos>'는 자기 스스로인 '<sos>'에 대해서만 Attention을 적용할 수 있고, '나는'은 '<sos>'와 '나는'을 Attention을 적용할 수 있습니다. 방법은 그림과 같이 Attention을 적용하면 안되는 정보에 대해 0으로 마스킹하여 참조할 수 없도록 합니다.
다음으로 Multi-Head Attention은 Encoder Block의 Multi-Head Attention과 거의 유사합니다. 다만, Key와 Value를 Encoder Block에서 출력된 벡터를 사용한다는 점에서 차이가 있습니다. 이는 Decoder Block이 현재 입력 뿐만 아니라 Encoder Block의 정보를 참조해야하기 때문입니다. 이 때문에 Decoder Block의 Multi-Head Attention은 Encoder-Decoder Attention이라고도 불립니다.
이외에 Feed Forward와 Normalization은 Encoder Block과 동일한 연산을 취합니다.