고정 헤더 영역
상세 컨텐츠
본문
- 본 글에서는 Topic Modeling을 진행하고 t-SNE를 사용하여 차원을 축소, 시각화합니다.
- 실습에는 Colab을 사용합니다.
0. Topic Modeling

Topic Modeling은 전체 문서에 대해 키워드의 확률 분포를 찾아내고, 군집화하는 비지도학습 알고리즘입니다. Topic Modeling에서 Topic은 키워드의 확률 분포 벡터가 됩니다. "Arts", "Budgets" 등은 알고리즘이 뽑은 Topic(index)에 대해 사용자가 임의로 부여한 의미입니다. Topic Modeling을 통해 얻을 수 있는 정보는 Topic, 그리고 얻은 Topic과 관련된 문서의 순서입니다. 이번 실습은 크롤링한 뉴스 제목 데이터에 대해 Topic modeling을 수행하고, 시각화하는 것입니다.
1. Import Package
이번 실습에 필요한 패키지입니다.
from bs4 import BeautifulSoup
from newspaper import Article
from time import sleep
from time import time
from dateutil.relativedelta import relativedelta
from datetime import datetime
from multiprocessing import Pool
import json
import requests
import re
import sys
from konlpy.tag import Okt
from collections import Counter
import json
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.decomposition import NMF
from sklearn.manifold import TSNE
from bokeh.models import HoverTool
from bokeh.palettes import Category20
from bokeh.io import show, output_notebook
from bokeh.plotting import figure, ColumnDataSource
2. Data Crawling
실습에 필요한 뉴스 제목 데이터를 크롤링합니다. 본인이 원하는 주제에 관련된 데이터를 크롤링합니다.
def crawl_news(query: str=None, crawl_num: int=1000, thread: int=4):
'''
Keyword arguments:
query : 검색어
crawl_num : 수집할 뉴스 기사의 개수
thread : multi-processing시 사용할 thread의 개수
'''
url = 'https://search.naver.com/search.naver?where=news&sm=tab_jum&query={}'
articleList = []
crawled_url = set()
keyboard_interrupt = False
t = time()
idx = 0
page = 1
res = requests.get(url.format(query))
sleep(0.5)
bs = BeautifulSoup(res.text, 'html.parser')
with Pool(workers) as p:
while idx < crawl_num:
table = bs.find('ul', {'class': 'list_news'})
li_list = table.find_all('li', {'id': re.compile('sp_nws.*')})
area_list = [li.find('div', {'class':'news_area'}) for li in li_list]
a_list = [area.find('a', {'class':'news_tit'}) for area in area_list]
for n in a_list[:min(len(a_list), crawl_num-idx)]:
articleList.append(n.get('title'))
idx += 1
page += 1
pages = bs.find('div', {'class': 'sc_page_inner'})
next_page_url = [p for p in pages.find_all('a') if p.text == str(page)][0].get('href')
req = requests.get('https://search.naver.com/search.naver' + next_page_url)
bs = BeautifulSoup(req.text, 'html.parser')
return articleListquery = 'Anything'
articleList = crawl_news(query)
3. Data processing
한글 명사와 알파벳만을 추출하여 Document-Term Matrix를 만들겠습니다.
# 형태소 분석기에는 Okt를 사용합니다.
t = Okt()
words_list_ = []
vocab = Counter()
tag_set = set(['Noun','Alpha'])
stopwords = set(['글자'])
# 크롤링한 ArticleList에서 각 뉴스 제목 별로 형태소만 남깁니다.
# 조건은 다음 세가지입니다.
# 1. 명사와 알파벳 2. 철자 길이가 2이상 3. Stopwords에 포함되지 않는 단어
for i, article in enumerate(articleList):
words = t.pos(article,norm=True, stem=True)
words = [w for w ,t in words if t in tag_set and len(w) > 1 and w not in stopwords]
vocab.update(words)
words_list_.append((words,article))
# 단어를 사용빈도 순으로 1만개까지 추출합니다.
vocab = sorted([w for w,freq in vocab.most_common(10000)])
# 단어와 인덱스 딕셔너리를 만듭니다.
word2id = {w:i for i,w in enumerate(vocab)}
# 10단어 이상으로 이루어진 기사제목에 대해 (단어,기사제목)의 튜플을 words_list에 담습니다.
words_list = []
for words, article in words_list_:
words = [w for w in words if w in word2id]
if len(words) > 10:
words_list.append((words,article))
del words_list_dtm = np.zeros((len(words_list), len(vocab)), dtype = np.float32)
for i,(words,article) in enumerate(words_list):
for word in words:
dtm[i,word2id[word]] += 1
dtm = TfidfTransformer().fit_transform(dtm)
4. Matrix decomposition
Document-Term matrix를 Non-Negative Factorization을 이용해 행렬분해 하겠습니다. H와 W로 행렬분해 되며 H의 차원은 (문서의수, K)이고, W의 차원은 (K, 단어의 개수)입니다. H의 Row는 각각 하나의 Topic을 의미하며 W의 Row는 각 문서가 Topic에 얼만큼의 가중을 줄 지에 대한 Weight입니다.
# 뉴스에 대해 5개의 Topic으로 나누어보겠습니다.
K = 5
nmf = NMF(n_components = K, alpha = 0.1)
W = nmf.fit_transform(dtm)
H = nmf.components_
print(W.shape,H.shape)# 각각의 Topic에 대해 가장 관련있는 단어 20개씩을 출력해보겠습니다.
for k in range(K):
print(f"{k}th topic")
for index in H[k].argsort()[::-1][:20]:
print(vocab[index], end=' ')
print('\n')# 전체 문서에서 각 Topic에 대해 가장 높은 관련성이 있는 3개의 뉴스 제목을 출력해보겠습니다.
for k in range(K):
print(f"==={k}th topic===")
for index in W[:, k].argsort()[::-1][:3]:
print(words_list[index][1])
print('\n')
5. visualization
t-SNE를 활용하여 Topic별 군집을 시각화하여 살펴보겠습니다.
from sklearn.manifold import TSNE
tsne = TSNE(n_components = 2 , init= 'pca', verbose = 1)
W2d = tsne.fit_transform(W)
topicIndex = [v.argmax() for v in W]output_notebook()
tools_to_show = 'hover,box_zoom,pan,save,reset,wheel_zoom'
p = figure(plot_width = 720, plot_height = 580, tools = tools_to_show)
source = ColumnDataSource(data = {
'x':W2d[:,0],
'y':W2d[:,1],
'id':[i for i in range(W.shape[0])],
'document':[article for words, article in words_list],
'topic' : [str(i) for i in topicIndex],
'color':[Category20[K][i] for i in topicIndex]
})
p.circle(
'x','y',
source =source,
legend = 'topic',
color = 'color'
)
p.legend.location = 'top_left'
hover = p.select({'type':HoverTool})
hover.tooltips = [('Topic','@topic'),('id','@id'),('Article','@document')]
hover.mode = 'mouse'
show(p)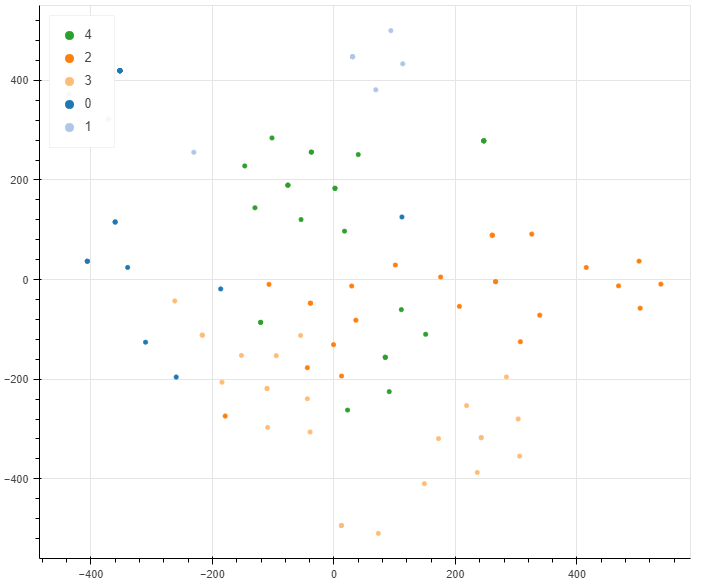
'NLP' 카테고리의 다른 글
| LSTM 연습 (0) | 2023.01.01 |
|---|---|
| Word2Vec Practice (0) | 2022.12.27 |
| Word Embedding (1) | 2022.12.27 |
| Bag Of Words (0) | 2022.12.26 |
| About NLP (0) | 2022.12.23 |





댓글 영역